Overview
- Package errgroup is a third party library available at golang.org/x/sync/errgroup.
- See example usage of package errgroup to manage a group of goroutines that are working on tasks.
- Use errgroup to implement a design pattern called the Scatter Gather Pattern.
Introduction
In this post, we will talk about Go’s errgroup package and use it to implement the Scatter Gather Pattern.
The package errgroup allows groups of goroutines working on subtasks of a common task to synchronize, propagate errors, and cancel context. This package is helpful because it takes care of the handling of tasks, managing, and returning errors. Without it, you may end up writing a lot of convoluted error handling code that makes your code harder to read and maintain.
The errgroup Package
Let’s go through some simple examples of using errgroup for synchronization, propagation of errors, and context cancellation.
Synchronization and Error Propagation:
In this example, we use errgroup to launch some tasks, and we synchronize the tasks by waiting for all of them to finish by calling the Wait() method. We also handle any error propagation, in this case Task 3 returns an error which is returned to the Wait() call.
An important thing to take note of is that Wait() will return the first non-nil error returned by a task.
package main
import (
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
eg := errgroup.Group{}
eg.Go(func() error {
time.Sleep(500 * time.Millisecond)
fmt.Println("Task 1 completed successfully")
return nil
})
eg.Go(func() error {
time.Sleep(300 * time.Millisecond)
fmt.Println("Task 2 completed successfully")
return nil
})
eg.Go(func() error {
time.Sleep(700 * time.Millisecond)
fmt.Println("Task 3 encountered an error!")
return fmt.Errorf("task 3 failed")
})
// Wait for all goroutines and collect the first error
if err := eg.Wait(); err != nil {
fmt.Printf("Error occurred: %v\n", err)
}
fmt.Println()
}
Output:
Task 2 completed successfully
Task 1 completed successfully
Task 3 encountered an error!
Error occurred: task 3 failed
Context Cancellation:
This example demonstrates how context timeouts cancel all goroutines early, with each task respecting the context signal.
Instead of using Group{} we use WithContext to wrap our time-out context.
package main
import (
"context"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
eg, ctx := errgroup.WithContext(ctx)
for t := range 5 {
taskID := t + 1
eg.Go(func() error {
for i := range 10 {
iter := i + 1
select {
case <-ctx.Done():
fmt.Printf("Task %d cancelled at iteration %d\n", taskID, iter)
return ctx.Err()
default:
fmt.Printf("Task %d - iteration %d\n", taskID, iter)
time.Sleep(500 * time.Millisecond)
}
}
return nil
})
}
if err := eg.Wait(); err != nil {
fmt.Printf("Execution stopped: %v\n", err)
}
fmt.Println()
}
Output:
...
Task 4 - iteration 4
Task 2 - iteration 4
Task 5 - iteration 4
Task 3 - iteration 5
Task 2 - iteration 5
Task 5 cancelled at iteration 5
Task 4 cancelled at iteration 5
Task 1 cancelled at iteration 5
Task 2 cancelled at iteration 6
Task 3 cancelled at iteration 6
Execution stopped: context deadline exceeded
Limiting Concurrent Tasks
In this example, we use SetLimit to control the amount of concurrency. SetLimit limits the number of active goroutines to a most n.
package main
import (
"fmt"``
"time"
"golang.org/x/sync/errgroup"
)
func main() {
maxConcurrent := 2
taskCount := 4
eg := errgroup.Group{}
eg.SetLimit(maxConcurrent)
for i := range taskCount {
taskID := i + 1
eg.Go(func() error {
fmt.Printf("Task %d started\n", taskID)
time.Sleep(1 * time.Second)
fmt.Printf("Task %d completed\n", taskID)
return nil
})
}
start := time.Now()
if err := eg.Wait(); err != nil {
fmt.Printf("Error: %v\n", err)
}
fmt.Println()
}
Output:
Task 2 started
Task 1 started
Task 2 completed
Task 1 completed
Task 4 started
Task 3 started
Task 3 completed
Task 4 completed
Notice how only two goroutines are running at any given time.
Scatter Gather Pattern
Now that we have seen some examples of how to use the errgroup package, let’s talk about how we can use this package to implement a very common and useful system design pattern called the Scatter Gather Pattern.
The Scatter-Gather Pattern is a messaging and processing pattern that is frequently used in distributed systems to partition work into parallel tasks and then merge the results. It is a commonly used pattern in database queries across shards, microservice orchestration, distributed search and load-balancing API calls. The benefits of this pattern are reduced latency, better resource utilization and fault tolerance through redundancy.
Here’s how it works:
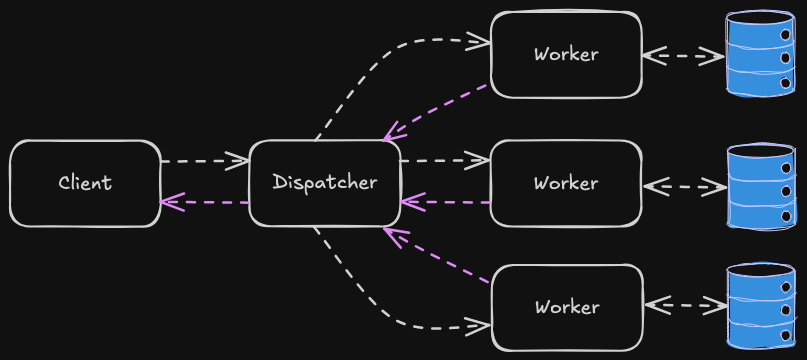
In the scatter phase:
- The dispatcher splits the request from the client into multiple sub-requests.
- The sub-requests are sent in parallel to multiple workers.
- Each worker processes the part it is assigned.
For example, imagine you are building a search engine that queries multiple sources (e.g. MySQL, Remote API, NoSQL) the search query is sent to all of them at once.
In the gather phase.
- The dispatcher collects results from all workers.
- The responses are combined into a single unified result. This step may include aggregation, filtering, sorting.
For example, the search engine collects all partial results from the workers then merges, removes duplicates and ranks them.
Code
Let’s now use errgroup package to implement the Scatter Gather Pattern.
We will simulate a search engine scattering a user’s query to multiple workers in parallel. Each worker will search its data store of products. Results will be merged, sorted and returned to the user much faster than querying sequentially.
These are the steps we want to take:
- Dispatcher will take a query request and break it into sub requests.
- Dispatcher will send each sub request to workers.
- Each worker will search its data store to process the request.
- Workers will return data to dispatcher for aggregation and sorting.
We will want to handle worker time-outs and failures scenarios as well.
Note: The code here is not meant to be production quality but is supposed to be a simple self-contained example.
Setup
We will be using Go 1.25 although errgroup is a very old package and earlier versions of Go should be completely fine.
$ mkdir app
$ cd app
$ go mod init app
$ go version
go version go1.25.5 darwin/arm64
$ go get golang.org/x/sync/errgroup
$ touch main.go
First, let’s create some fake data stores that our workers will search:
type Search func(context.Context, string) ([]Result, error)
func fakePostgres(_ context.Context, query string) ([]Result, error) {
time.Sleep(500 * time.Millisecond)
return []Result{
{
Type: "phone",
Manufacturer: "Apple",
Model: "iPhone 15",
Source: "postgres",
Price: 799.99,
},
{
Type: "phone",
Manufacturer: "Samsung",
Model: "Galaxy S24 Ultra",
Source: "postgres",
Price: 1299.99,
},
{
Type: "phone",
Manufacturer: "Google",
Model: "Pixel 8 Pro",
Source: "postgres",
Price: 899.99,
},
}, nil
}
func fakeMongoDB(ctx context.Context, query string) ([]Result, error) {
select {
case <-time.After(30 * time.Second):
case <-ctx.Done():
}
return nil, nil
}
func fakeMySQL(_ context.Context, query string) ([]Result, error) {
time.Sleep(700 * time.Millisecond)
return []Result{
{
Type: "headphones",
Manufacturer: "Sony",
Model: "WH-CH720N",
Source: "mysql",
Price: 149.99,
},
{
Type: "phone",
Manufacturer: "Samsung",
Model: "Galaxy Z Fold 5",
Source: "mysql",
Price: 1799.99,
},
{
Type: "tablet",
Manufacturer: "Samsung",
Model: "Galaxy Tab S9 Ultra",
Source: "mysql",
Price: 849.99,
},
}, nil
}
func fakeRedis(_ context.Context, query string) ([]Result, error) {
return nil, fmt.Errorf("error redis: key eviction due to memory pressure")
}
fakePostgres and fakeMySQL returns some data after a small delay (to simulate workload). fakeMongoDB takes 30 seconds to respond, which in our example will cause this worker to time out. And fakeRedis returns no data but an error instead.
Next, we will create our Worker type and a Run function:
type Worker struct {
ID int
Query string
Timeout time.Duration
Search Search
}
func (w *Worker) Run() ([]Result, error) {
ctx, cancel := context.WithTimeout(context.Background(), w.Timeout)
defer cancel()
done := make(chan struct{})
var results []Result
var err error
go func() {
results, err = w.Search(ctx, w.Query)
done <- struct{}{}
}()
select {
case <-done:
return results, err
case <-ctx.Done():
return nil, ctx.Err()
}
}
The Run function will actually run a search against what ever fake data store we have assigned (e.g. fakeRedis). We need to handle the case where searching a data store takes too long (in this case, fakeMongoDB which takes 30 seconds to run). So we run the search in a separate goroutine and send a message on the done channel, once the function completes. If the message does not arrive on the done channel, the timeout fires, ctx.Done() sends a signal and the search function checks it and exits cleanly.
Next, we will create the Dispatcher type with a Search function:
type Dispatcher struct {
Timeout time.Duration
}
func (d *Dispatcher) Search(query string) *AggregatedResults {
var (
datastores = []Search{
fakePostgres,
fakeMongoDB,
fakeMySQL,
fakeRedis,
}
eg = errgroup.Group{}
agg = &AggregatedResults{}
resultsChan = make(chan []Result, len(datastores))
)
for idx, search := range datastores {
w := Worker{
ID: idx + 1,
Query: query,
Timeout: d.Timeout,
Search: search,
}
eg.Go(func() error {
results, err := w.Run()
resultsChan <- results
return err
})
}
// wait for all the workers to complete
go func() {
if err := eg.Wait(); err != nil {
agg.Errors = append(agg.Errors, err.Error())
}
close(resultsChan)
}()
// merge results
for result := range resultsChan {
agg.Total += len(result)
agg.Results = append(agg.Results, result...)
}
// sort by price
slices.SortFunc(agg.Results, func(a, b Result) int {
return cmp.Compare(a.Price, b.Price)
})
return agg
}
The dispatcher will create one worker for each data store that we want to search. We then use the errgroup package to start each worker and then wait for all workers to finish. After the workers finish, we merge the results and then sort the results by price.
Let’s tie this all together in the main function:
func main() {
query := "phoneANDtabletANDheadphones"
dispatcher := &Dispatcher{
Timeout: 3 * time.Second,
}
results := dispatcher.Search(query)
var out bytes.Buffer
enc := json.NewEncoder(os.Stdout)
enc.SetIndent("", " ") // 2‑space indent
if err := enc.Encode(results); err != nil {
fmt.Fprintln(os.Stderr, "encode error:", err)
}
fmt.Println(out.String())
}
In the main function we have our query "phoneANDtabletANDheadphones" which would be passed to us by some client (see diagram above).
We instantiate our dispatcher passing in a timeout (take note of the three second timeout). We pass our query to the dispatchers Search function, which then kicks off the scatter gather process described earlier. Finally, the last thing to do is to take the aggregated results and then print them to the console in JSON format.
Let’s run the code and see the output:
$ time go run main.go
{
"total": 6,
"results": [
{
"type": "headphones",
"manafacturer": "Sony",
"model": "WH-CH720N",
"source": "mysql",
"price": 149.99
},
{
"type": "phone",
"manafacturer": "Apple",
"model": "iPhone 15",
"source": "postgres",
"price": 799.99
},
{
"type": "tablet",
"manafacturer": "Samsung",
"model": "Galaxy Tab S9 Ultra",
"source": "mysql",
"price": 849.99
},
{
"type": "phone",
"manafacturer": "Google",
"model": "Pixel 8 Pro",
"source": "postgres",
"price": 899.99
},
{
"type": "phone",
"manafacturer": "Samsung",
"model": "Galaxy S24 Ultra",
"source": "postgres",
"price": 1299.99
},
{
"type": "phone",
"manafacturer": "Samsung",
"model": "Galaxy Z Fold 5",
"source": "mysql",
"price": 1799.99
}
],
"errors": [
"error redis: key eviction due to memory pressure"
]
}
real 0m3.827s
user 0m0.136s
sys 0m0.150s
We got a total of six results from the data stores fakePostgres and fakeMySQL, the fakeRedis returned an error which is also recorded in the aggregated results.
Notice that the dispatcher took three seconds to run real 0m3.827s, why? We set the dispatcher timeout to three seconds, which means we want all the workers to finish by this deadline. Workers searching data stores fakePostgres, fakeMySQL and fakeRedis all return within this time limit. However, the dispatcher is waiting for the worker searching data store fakeMongoDB to return. It does not, as we set the function to return after thirty seconds, so after three seconds the time-out triggers, and we cancel the goroutine and the dispatcher progresses into the merge and sort phases.
If you would like to see the entire code, it is available at this playground.
Thank you for reading.